
Chapter 4: Traditional Models of Human Communication
This chapter reviews traditional theoretical models of human communication, from both the discipline of communication and other areas of study. It focuses on the “code model”, a generalized model outlining the traditional conceptualization of how human communication works. After describing this model, it identifies several shortcomings with this model, most notably the range of everyday situations and experiences that it cannot adequately address.
To explore, visualize, and study how processes work, scholars will often create models. Models are essentially (simplified) representations of an object, process or system that depict relevant functional or structural qualities (Pavitt, 2010, 2016). How the process of (human) communication works has been a longstanding topic of scholarly and philosophical interest, and has been approached (from various angles) by scholars from a number of different disciplines, including philosophy, linguistics, psychology, education, and communication. Members of each discipline have developed models focusing on different features or aspects of the communicative process, sometimes in specific contexts. As such, many different conceptual models of human communication, and of sub-processes involved in it, have been put forward.
Models in the Discipline Communication
Within the field of communication, three general categories of models have been put forward to describe the process of human communication: linear, interactive, and transactional models (e.g., McCornack, 2010). If you have taken an introductory course in communication, you have likely encountered one or more of these models.
Linear models (e.g., “source-message-receiver” models) of human communication present communication as a series of activities moving information from a source to a receiver. One prominent example of this is Shannon and Weaver’s (1949) model. In this and other linear models, a source packages (i.e., encodes) information content into a message that can be transmitted (which these models often refer to as a signal). The source then sends that message through a channel to a receiver. As the message travels through the channel, noise—conceptualized as environmental factors that interfere with message transmission—can distort the message, or prevent it from reaching its destination. Assuming the message is able to reach its destination in some kind of recognizable form, a receiver detects and accepts the message (including any changes to it made by noise during transmission). The receiver then unpackages (i.e., decodes) the sender’s message back into information content. This completes the process of information being transmitted via messages (or signals) from source to receiver. As you may have guessed, this model draws heavily on telecommunications and signal processing as analogues for human communication.. This results in a number of shortcomings, the most obvious of which that much human communication does not occur as a single, unidimensional transmission. Rather, as discussed in Chapter 2, it is interactive.
Interactive models of human communication present human communication as a bi-directional (and potentially cyclical) process between sources and receivers. One prominent example of this is Schramm’s (1954) model of communication. In this and other interactive models, the basic processes and components outlined in a linear communication model are still present. However, two new elements are present: first, receivers can provide feedback to sources (which may ultimately begin a new cycle of through the model, where source and receiver switch roles). Second, both source and receiver have fields of experience (e.g., beliefs, attitudes, values, knowledge) that they bring to the interaction. These can influence the way that people send and interpret messages, and thus how easily people understand each other. While interactive models do a better job incorporating influence from a receiver than do linear models, many have argued that they still do not adequately recognize the role of the “receiver” in the creation of meaning.
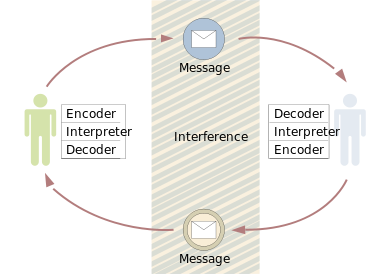
Transactional models of human communication were developed to address these concerns. One prominent example of this is Watzlawick, Beavin and Jackson’s (1967) model. In transactional models (e.g., Miller & Steinberg, 1975), communication is presented as inherently collaborative. Rather than designating a “source” and “receiver”, these models designate both (or all) interactants as responsible for the co-creation of meaning. In this, communicators are conceptualized as interdependent, and as capable of influencing each other on an ongoing basis throughout the interaction. This offers a fundamentally different conceptualization of communication than linear and interactive models, and one that is more consistent with a an understanding-focused approach to studying communication (see Chapter 2). However, in line with the values and priorities of traditional communication research, the focus of transactional models (particularly that of Watzlawick et al., 1967) is generally on the social and relational consequences of communication. Although they acknowledge that both or all communicators affect each other and construct meaning together, they do not say much about the means by which this occurs. Rather than being detailed, functional representations of the process of human communication, these models are more heuristic and abstract in nature. As such, transactional models they do not actually provide very much insight into how people create mutual understanding in interaction—that they do so is essentially taken as a given, rather than explicated.
In this text, our goal is to study how people create mutual understanding in interaction. To a degree, these models provide insight into how this can occur. Collectively, they identify key components of communication as a process: people (either designated as sources/receivers or as communicators), mental environments (cf. “fields of experience”) of those entities, messages, some form of message transmission, and the sharing of information or creation of meaning as an outcome. However, like traditional definitions of communication reviewed in Chapter 2, these models do not really provide insight into how people create meaning or mutual understanding. While they do lay out a series of events that (theoretically) comprise communication, scholars’ use of these models has tended to focus on outcomes rather than the functional details, of communicative processes. As noted at the outset, this is likely a result of the communication discipline’s historical focus on influence, rather than understanding, as its primary outcome of interest.
In other disciplines such as linguistics, psychology, and education, there has been a more focused and concerted effort to try to model processes of message comprehension and/or understanding. Scholars in linguistics have generally approached this issue with an emphasis on comprehension of language (i.e., verbal stimuli, as opposed to nonverbal stimuli), with different sub-disciplines focusing on the structure and processing different components of human language (e.g., syntax, lexicon). (An important exception to this is research in pragmatics, which focuses on how people interact and make meaning in context. Prominent scholars in pragmatics have argued for the need to approach this topic differently than other sub-disciplines of linguistics have, and we will return to this point later). Scholars in psychology have generally approached this issue with an emphasis on the cognitive processes involved in comprehension such as attention; perception; and memory encoding, storage, and recall. Scholars in education have generally approached this issue with an interest in reading and thus text comprehension—often motivated by a need to diagnose and address reading difficulties—as well as developmental aspects of this process (as it relates to the creation of age-appropriate materials).
The Code Model
Although the models developed by these scholars differ in their details, many share a common set of implicit assumptions about how communication functions. (These assumptions are shared by the linear and interactive models of communication described above). Generalized, this conceptualization of the process of human communication is referred to as the code model (Sperber & Wilson, 1986; Scott-Phillips, 2015).
The basic logic of this model is that mental representations cannot actually travel across time and space, because they are conceptual abstractions (i.e., as thoughts, ideas, meme states), and do not have a physical form. However, if they are converted into something that has a physical form, then this signal (i.e., set of physical stimuli which stand for the mental representation of interest) can travel in space and time. If an entity can convert the physical signal back into a conceptual abstraction at its destination, then this allows thoughts or ideas to “travel”. To be able to reliably convert or translate mental representations into signals, and signals into mental representations, codes—that is, systems that reliably pair stimuli (signals) with meme states (mental representations)—are required.
According to the code model, communication occurs via encoding and decoding of messages, which function as signals. In this process, a source (or sender) converts a meme state (i.e., thought, idea), into a message (i.e., set of stimuli; signal), using a code. This is encoding. This message, or signal, is then transmitted through some kind of medium from Point A to Point B, across space and/or time. During the transmission process, the signal can be distorted, disrupted, or otherwise affected, meaning that the set of stimuli that “arrive” at a destination may not be identical to what was “sent” from a source. Assuming some kind of signal arrives, a target (or receiver) converts the message back into a meme state, using the same code that the sender initially used. This is decoding. If this process is successful, then the target will end up with the same meme state, or mental representation (as a conceptual abstraction) that the source had at the start of the process. In other words, one person’s mental representation will have effectively “traveled” from one point to another.
Several important assumptions are implicit in the code model.
- First, as its name suggests, this model treats codes as essential to communication. In the code model, codes are the means by which meme states (as abstractions) can be converted into and out of messages.
- Second, and following from this, this model relies on the application of systematic associations as the primary mechanism by which communication occurs (i.e., using “entries” in a code book: connecting pairs of meme states and stimuli).
- This leads us to a third assumption: the key skill or ability required to communicate is representing and applying associations. Any entity that can reliably associate stimuli (i.e., messages or signals) with corresponding meme states (i.e., mental representations) following a set of clearly defined rules (i.e., a code, which pairs them together) should be able to communicate effectively.
- Accordingly, the “meaning” of a message—that is the information content it represents—is relatively stable and fixed: the message’s form and meaning should be clearly and reliably linked (via a code), and as such can be seen as a property of the message (as a set of stimuli, operating as a signal).
A final, implicit assumption of the code model is that senders and receivers perform their respective operations—encoding and decoding—independent of each other. Because codes are established systems consisting of reliable pairings of stimuli and meme states, there is no real need for them to work together, as long as they both know the code being used. As a consequence of this, there is no theoretical problem with researchers focusing on one person, or role (i.e., sender or receiver), at a time when studying communication processes. Thus, this model allows, and to an extent encourages, treating the individual as the primary unit of analysis in research (for a further discussion of this issue, see Chapter 2).
Research with the Code Model
The code model was—and in many academic areas, continues to be—a dominant conceptual approach to studying communication. As a result, its assertions and assumptions have shaped a large body of research across different disciplines. In particular, the code model’s emphasis on encoding and decoding have led researchers to focus on the mechanics of these processes, and the mechanisms involved in them. Researchers interested encoding have studied topics like speech production processes; much of this work is in psychological sciences and to some extent, communication sciences and disorders. Research and theorizing on message construction and audience design are areas of study that address encoding at a more abstract level, although researchers in these areas do not necessarily position their work as being about encoding per se. Researchers interested in decoding have generally studied comprehension processes, in a range of different domains. Models of text comprehension (e.g., Kintsch & Van Dijk, 1978), discourse comprehension (e.g., Graesser, Millis, & Zwaan, 1997) and reading comprehension (e.g., Lorch & van den Broek, 1997) are just a few examples of this kind of domain-specific work. All of this research, both theoretical and empirical, is built on the foundation of the code model, and can be seen as a direct result of conceptualizing communication as a process of encoding, transmitting, and decoding messages.
Critiquing the Code Model
Like any theoretical model, the code model has both strengths and weaknesses. First, let us consider its strengths. As its widespread use in scholarship and research would suggest, it clearly does have something to offer those interested in explaining how communication works. First and perhaps foremost, the code model does appear to describe observable phenomena involved in communication in a sensible and useful way. In this, the model seems to have face validity: that is, it “looks” right when we consider it together with our everyday experiences (particularly those involving verbal communication). As such, the model is intuitively appealing. As just discussed, it has also formed the foundation of the large body of scholarly work, which means it has been useful resource for many people studying communicative phenomena.
Additionally, the code model has received some degree of empirical support. Many of the domain-specific models mentioned above, which focus on processes of encoding and decoding, have been tested, refined, and supported across numerous research studies. These models can also be quite useful in helping people recognize where problems with communication or comprehension arise. For instance, models of reading comprehension provide a set of mental “steps” and corresponding skills involved in the decoding of written texts. These steps can be used to help diagnose where reading difficulties are occurring as they direct researchers’ (or educators’) attention to key variables in the process of reading comprehension (e.g., word comprehension vs. combining words into sentences vs. relating the content of sentences to one another). Likewise, these models can also serve as a basis for developing educational programs and interventions to address deficits and/or improve skills needed for successful reading (and decoding more generally).
However, scholars have also pointed out a number of issues, or weaknesses, that the code model has. Most importantly, its critics argue that the code model cannot fully explain much of everyday communication, particularly face-to-face interpersonal interactions. Although the model easily describes and explains how a person would interpret a literal statement (e.g., “It is cold in here” to mean, “The temperature is low in this location”), it does not do as well explaining how people successfully create understanding and share meaning using non-literal or indirect statements (e.g., “It’s cold in here” to mean, “Please close the window”). If the primary means by which people share meaning is through a code—that is, a system that pairs stimuli and memes—it is difficult to explain how people manage to successfully decode non-literal or indirect messages, as their intended meaning does not directly correspond to what is “coded” into the words that speakers use.
Many scholars have sought to address this issue within the paradigm of the code model. For example, some have suggested that we comprehend metaphors, which are one type of non-literal statement, by first processing the literal meaning and then searching for an alternative when the literal meaning does not fit the context (e.g., Clark & Lucy, 1975). However, others, and their empirical findings, have challenged this model of metaphor comprehension (e.g., Gildea & Glucksberg, 1982). These researchers suggest that people can and do access the meaning of a metaphor directly, often with the help of the context, which makes certain concepts or ideas more or less salient (that is, easily accessible in our minds). This kind of processing explanation still could, conceivably, be seen as consistent with the code model: one could argue for particular code “entries” being accessed differentially in different contexts, or for different “rules” or associations being systematically applied to distinguish literal and non-literal usage. However, the fact that it takes these extra twists and turns to create a viable explanation shows that these situations do not really fit cleanly or comfortably within a code model’s framework.
Similar problems arise when we attempt to explain situations where people successfully communicate using ambiguous stimuli—that is, stimuli that do not necessarily have a clearly delineated memes or meme states associated with them. Nonverbal stimuli (e.g., shared glances, sighs, gestures) frequently fall in this category: the same expression or action can have a wide variety of different meanings—so many that the stimulus itself does not necessarily have a clear “definition”, or entry in a code book. This kind of communication in fact happens quite frequently in our daily lives, but the code model struggles to explain how people manage to understand each other in these circumstances.
Another situation that the code model struggles to explain is how people interact when they do not share a common code. Consider, for example, a situation in which two people who do not speak the same language try to communicate. (If you have ever travelled to a country or region where you did not speak the local language, you may have had this experience yourself). Although they do not initially have a code to rely on—which, according to the code model, is required for communication—they are often able to create mutual understanding well enough for their purposes. How do people manage this? In some cases, interactants may be able to switch from their “default” code (e.g., native language) to another code that is shared with their interlocutor (e.g., second or foreign language; use of a kinesic code like conventional gestures). For example, someone who speaks Japanese (but not Tagalog) and someone who speaks Tagalog (but not Japanese) might be able to have a conversation in English if they both know English (as a second language). Through this adjustment, they are able to create a situation in which a common or shared code becomes available. However, this kind of adjustment is not always an option. When it is not, people often use ambiguous nonverbal stimuli (e.g., gestures, facial expressions, pointing at objects) to try to express and share their thoughts with others. This then returns us to the scenario we considered in the previous paragraph—communicating using ambiguous stimuli—which is sometimes possible, but usually not easy, to explain in terms of the code model.
A final, related criticism of the code model is that it cannot adequately explain situations where people use instantaneous conventions, or improvise, to communicate. Instantaneous conventions are communicative practices (established by usage) that are generated “on the spot” in an interaction (Misyak, Noguchi & Chater, 2016). Because they are not formalized or set before an interaction, the associations between memes and stimuli in such conventions are generally flexible: the same stimulus can be used to indicate one or more different memes, both within and between conversations. For example, waving one’s hand in a particular way might be used to indicate, “that’s enough, stop” in one instance; later in the conversation, the same motion might be used to indicate, “go ahead, add some more”. In a study by Misyak and colleagues (2016), the researchers set up a game in which players had to work together to open boxes containing rewards, and avoid opening boxes that contained punishments. One player knew what was in each box but could not open them; the other player had a digital tool to open boxes, but did not know what was in each box. Depending on the resources available for communication and the configuration of rewards and penalties in the boxes in different rounds, the players were observed using the same signal (e.g., placing a digital token on a box) to indicate (a) “open this box” and (b) “do not open this box”.
This kind of communicative behavior is very difficult to explain with the code model, which relies on stable associations between memes and stimuli to explain how meaning is shared via messages. Indeed, a code in which the same sign (e.g., a hand wave) could indicate two opposite meanings (e.g., both “yes” and “no”) is not very helpful or useful for communicating, if that code is the only means we have to create mutual understanding with another person. That people use instantaneous conventions (as well as use more established conventions in novel and flexible ways) to share meaning, and that they do so successfully, suggests that there must be more to human communication than the code model tells us.
When we look across the strengths and weaknesses of the code model, we can see some patterns emerge. First, as its name would suggest, the code model “works” best when there is an established, shared code used by all communicators, and this code has relatively rigid syntax. Second, this model is also best for direct and/or literal statements, because they can be encoded and decoded with minimal ambiguity. These qualities generally characterize what cognitive and computer scientists call “well-posed problems”: tasks or situations that have a clear “right” answer that one can arrive at by systematically applying sets of rules. However, the code model does not work as well for situations where there is not a shared, established code; stimuli are ambiguous; signals are being improvised; or syntax is less rigid and increasingly probabilistic. These qualities generally characterize what are called “ill-posed problems”—that is, problems that do not have a clear “right” answer that one can determine or calculate using sets of pre-defined rules. In short, the code model appears to work reasonably well for well-posed (communicative) problems, but not for ill-posed problems.
Thinking about it this way, we can see that the code model is not necessarily wrong or inaccurate, but it is incomplete as a model of human communication: it is only able to tell us how things work in a subset of situations. For better or for worse, much of human communication is an ill-posed problem, rather than a well-posed one. Thus, the processes outlined in the code model need to be either augmented, or reconsidered, to be able to get the “whole” story—that is, to be able to describe and explain the wide range of situations and experiences that constitute human communication.
References
Clark, H. H., & Lucy, P. (1975). Understanding what is meant from what is said: A study in conversationally conveyed requests. Journal of Verbal Learning and Verbal Behavior, 21, 85–98.
Gildea, P., & Glucksberg, S. (1982). On understanding metaphor: The role of context. Journal of Verbal Learning and Verbal Behavior, 22, 577–590.
Glucksberg, S., & Keysar, B. (1990). Understanding metaphorical comparisons: Beyond similarity. Psychological Review, 97, 3–18.
Graesser, A. C., Millis, K. K., & Zwaan, R. A. (1997). Discourse comprehension. Annual Review of Psychology, 48, 163–189.
Kintsch, W., & Van Dijk, T. A. (1978). Toward a model of text comprehension and production. Psychological Review, 85(5), 363.
Lorch, R. F., Jr., & van den Broek, P. (1997). Understanding reading comprehension: Current and future contributions of cognitive science. Contemporary Educational Psychology, 22(2), 213–246.
McCornack, S. (2010). Reflect and relate: An introduction to interpersonal communication (2nd edition). Boston: Bedford/St. Martin’s.
Miller, G. R., & Steinberg, M. (1975). Between people: A new analysis of interpersonal communication. Chicago: Science Research Associates.
Misyak, J., Noguchi, T., & Chater, N. (2016). Instantaneous conventions: The emergence of flexible communicative signals. Psychological Science, 27(12), 1550-1561.
Pavitt, C. (2010). Alternative approaches to theorizing in communication science. In C. R. Berger, R. E. Roloff, & D. R. Roskos-Ewoldsen (Eds.), The handbook of communication science (pp. 37–54). Thousand Oaks, CA: Sage.
Pavitt, C. (2016). A survey of scientific communication theory. New York: Peter Lang.
Schramm (1954). Process and effects of mass communication. Urbana: University of Illinois Press.
Scott-Phillips, T. (2015). Speaking our minds. New York: Palgrave Macmillan.
Shannon, C. E., & Weaver, W. (1949). The mathematical theory of communication. Urbana: University of Illinois Press.
Sperber, D., & Wilson, D. (1986). Relevance: Communication and cognition. Oxford: Blackwell.
Watzlawick, P., & Beavin, J. H. (1967). B., & Jackson, D. D. (1967). Pragmatics of human communication: A study of interactional patterns, pathologies, and paradoxes. New York: Norton.

{kind=link}